MySQLを学んだ備忘録を共有したい。内容が圧倒的に足らず、曖昧な箇所も多いので、その都度更新していく予定。

基本的な動作
Vagrantへログイン

「MyVagrant」というディレクトリに「MyCentOS」というディレクトリを作成して、その中にVagrantのファイルを入れているので、ホームディレクトリからアクセスする場合は「MyVagrant」、「MyCentOS」へまずは進む。そこから「vagrant up」と入力することでVagrantを実行できる。

そのあとに「vagrant ssh」でVagrantにログインすることができる。
データベースの作成とアクセス権付与

このように「test_db」というデータベースを新規作成し、「testuser」に「test_db」へのアクセス権を付与した。

一度、「\q」で「root」ユーザーを抜けて「testuser」でアクセスに成功した。
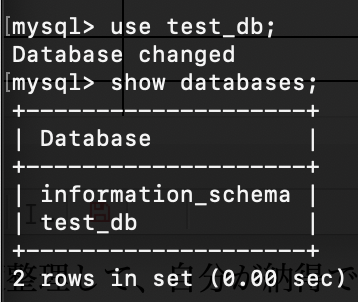
「test_db」にアクセスできている。データベース一覧を表示しても権限が与えられたデータベースしか閲覧できない。
現在のユーザーを確認する
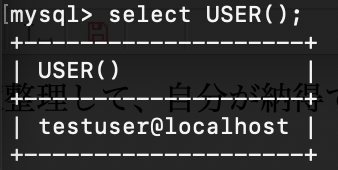
テストユーザーを確認できた。
テーブルを作成、確認、内容表示
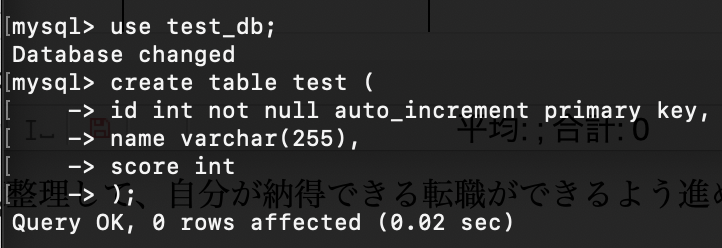
テーブル作成
確認
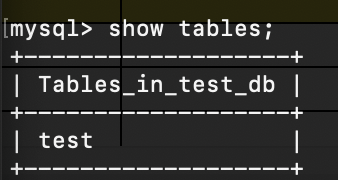
内容表示

「view」と「table」の違い
「view」はSELECTで条件に応じて抽出したデータに名前をつけてあたかもテーブルのように扱える機能。ある条件で抽出したデータに名前をつけて閲覧することができる。
「table」は元のデータを使って新しいテーブルを作成するもので、作成したテーブルは独立して動き始めて、元のデータの値を反映しない。「view」を使うことで、可変的なテーブル(のような、でも実態のない)を作ることができる(と言っても実態はない)。
「view」はテーブルではないので、元の値が変わると「view」の値も変更する
しかし「view」はテーブルと同じ扱いになるので、「show table」で確認することもできる。しかし、テーブルとviewが一緒になって表示されて、どれがテーブルでどれが「view」かわからなくなる可能性もあるようだ。その辺りをググってみるとややこしいコードがたくさん出てきたが、「どのようにViewが作られたか確認できるコマンド」があることを見つけ、それを実行すればテーブルか「view」かの区別が簡単につく。以下のコード。
「show create view 'ここにViewの名前';」
'ここにViewの名前'のところに、もしテーブル名が入っているとエラーになるので、入力した名前のものがテーブルなのかView七日の判別が簡単なコマンドで確認できる。これで二つの区別がつく。
トランザクションを使う利点
トランザクションとは処理する箇所の開始と終わりを指定してまとめて処理する場合に使う。
開始は「start transaction;」
終わりは「commit;」
とコードを書く。
処理する箇所をまとめることで色々といいことがあるようだ。
トランザクションを使う利点をとりあえず少しだけ理解した。
一連の処理をまとめることで、その中身の処理を完全に終わらせるか途中で不適切な処理があった場合に完全に処理しないか、つまり処理の「ON」と「OFF」がはっきりしているので、ややこしくなくなる。
不具合が起きた時には、まとめて処理した変更をまとめて破棄することもできる。つまりトランザクション実行前のデータベースの状態に戻すことができる。
その時には
「commit;」の代わりに「rollback;」とコードを書くことで処理できる。
処理が2つあるとして、1つ目の処理が成功したのに、2つ目の処理がうまくいかなかった時が不具合という意味で、1つだけ処理されてしまうことがないという保証を得られる。2つの処理は必ずセットで処理されるようになる。
ネットに優しく書いてある情報がなかったので、自分でいくつか検証してみた。
①トランザクションの後付けはできない。
トランザクションをつけないで、2つの処理を実行して2つ目の処理にエラーを出させた。1つ目の処理だけ反映されている状態にした。その上で、「start transaction」と「rollback」を「後付け」で書いてみたが、元に戻ることはなかった。
②「commit」もしくは「rollback」で閉じていないと、頭に「start transaction」をつけていてもトランザクションは機能しない。上の「1.」の場合と同じように、後から処理を戻そうと思って「rollback」を後付けしてもデータは戻らない。
③コミットすると、その処理は取り消せない。
「commit」で閉じて、その処理がエラーなしに完了すると、そのあとに「rollback」を入力してもデータは戻らない。エラーの場合にのみ「rollback」は役に立つ。処理を片方だけ(もしくは複数)成功して、片方だけ(もしくは複数)失敗した時にのみ「rollback」は役に立つ。
複数の処理をするときに、一連の処理を確実に頭からけつまで完結させたいときに役に立つ。何かの処理だけ成功して、何かの処理だけ失敗して、数値がめちゃめちゃになってしまった、どこがどこに影響しているのかわからない、といった状況を防ぐことができるのだと思う。
索引
索引はデータの抽出処理が遅いなと感じた時などに、特定のカラムに索引をつけることで高速化することができる。
必要ないときはつける必要はない。
つけるべきかどうかの検討が必要。
4.内部結合・外部結合
内部結合・外部結合とは共に、2つ以上のテーブルのデータを紐付ける処理。
2つ以上のテーブルのデータをまとめてから抽出できるという効果を生む。
内部結合は「inner join」というコマンドを使い、外部結合は「outer join」というコマンドを使う。
内部結合はテーブルに共通しているデータのみを結合する。
外部結合はテーブルに共通していないデータもレコードに追加していく。テーブルの軸を決める必要があり、コマンドも異なってくる。
「inner join」は
「select * from 1つ目のテーブル名 inner join 2つ目のテーブル名 on 1つ目のテーブル名. (コンマ)紐付けたいカラム名(テーブル1) =紐付けたいカラム名(テーブル2)」
となる。
「outer join」は
「select * from 1つ目のテーブル名 left(or right) outer join 2つ目のテーブル名 on 1つ目のテーブル名. (コンマ)紐付けたいカラム名(テーブル1) =紐付けたいカラム名(テーブル2)」
となる。
「inner」「outer」は省略できるので、二つの違いは「left」「right」がついているかで判断できる。「left」か「right」がついていれば外部結合となる。
外部結合で、「left」を入力すると左のテーブルが軸になり、「right」を選択すると右のテーブルが軸になり抽出される。
例えば「posts」と「comments」という2つのテーブルを作る時は以下のようになる。

抽出される時、カラムの順番は「left」でも「right」でも常に左側からテーブル1からテーブル2となる。

と「left」と入力して抽出すると、
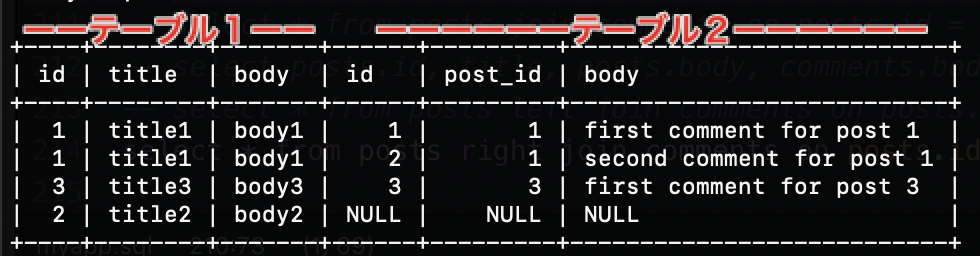
と、こんな感じになる。

と「left」と入力して抽出すると、
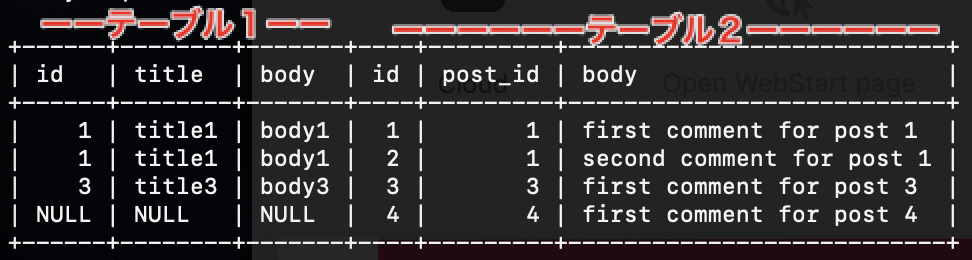
と、こうなる。
「left」でも「right」でも常に左側からテーブル1からテーブル2となっているのがわかる。
左から3つ分のカラムはテーブル1を表示していて、4、5、6番目のカラムはテーブル2の内容が反映される。そのように覚えておけばと割と見やすい。NULLは値がないことを表しているが「軸のテーブルから見て値がない」と考えると納得しやすい。
5.外部キー制約
外部キー制約とは、2つのテーブルで親子関係をもたらすこと。親子関係をもたらし、2つのテーブルの整合性を保つ役割を果たす。
親のテーブルに存在しないRaw(列)を子が持っていたとして「outer join」で結合したら、子のテーブルにだけ存在することになり、おかしなデータになる。
ブログサイトで考えてみる。ブログサイトならば記事を保存しておくテーブルと、コメントを保存しておくテーブルが少なくとも必要になるだろう。親のテーブルとなる記事の入っているテーブルには、記事1から記事3までのデータが入っているとする。それなのに、子のテーブルとなるコメントの入っているテーブルには記事4のコメントが入っていたらおかしなことになる。
外部キーで親子関係を作ることにより、このような不整合を防ぐことができる。外部キー制約をかけると、親のRawを削除することもできなくなる。子だけに存在するRawという変な状況を防ぐためだ。
コマンドでは、外部キーの名称をつけるのと、テーブルの親子関係を決めるために「reference」とコードを書いてどちらを参照元とするのかなどを設定する。紐付けるカラムの型は一致させる必要がある。
と、書いてみたが、外部キー設置時のオプションは4種類くらいあるようなので、親子関係も色々と変化するようだ。
とりあえず、親子関係をつくることができるということと、親子の間で制約が生まれて勝手に更新や削除をしようとするとエラーが出るというくらいの認識にとどめておく。
6.トリガー
トリガーとは、何かの処理が行われたら、それを契機にして、他のテーブルに反映させるコマンド。
色々使い方があるよう。
7.日時の抽出
日時の抽出は、様々な機能がある。
レコードを作成した日付け、更新した日付けなどを抽出できる。
2週間後の日付けを抽出したり、日付けを数字だけでなく文字で抽出することもできる。
8.データの復元
データの復元には「mysqldump」を使用する。
リダイレクションでバックアップ元のデータを、他に新しく作っておいた「sql.」ファイルに流し込んでおく。
方法は「mysql」から一度抜けて、Localhostから「mysqldump」のコマンドを入力してリダイレクションする。
元のデータをうっかり消してしまった時は、MySQLで元のデータベースにアクセスしている時に「source」コマンドでバックアップデータを呼び出して復元すればよし。